

正規化とか正則化って、似ている言葉が多くてややこしいですよね。言葉の意味も、なんとなくわかるけど、はっきりとは理解できないモヤモヤワード。正規化という言葉だけでもいろいろなところで違う意味で使われるからまた混乱するんですよね~。 ということで、今回は「バッチ正規化」を整理してみましょう。
1. ディープラーニングで出力が偏る?
深層学習(DL)の基本構造についてはこちらの記事を参照してください。簡単に言うと、DLモデルは「入力層→中間層→出力層」を順番に通して学習します。各層では特徴を抽出して次の層に渡しますが、学習が進むとある層の出力が特定の値に偏ることがあります。
- 例えば、ある層の出力が全部「8〜10」に集中してしまう
- その場合、次の層が受け取る情報に差がなく、学習が進みにくくなる
- データをもとに計算(ReLuなどの活性化関数)を通すとさらに偏りが強くなる
この状態は「出力が偏って学習が停滞しやすい状態」と考えられます。
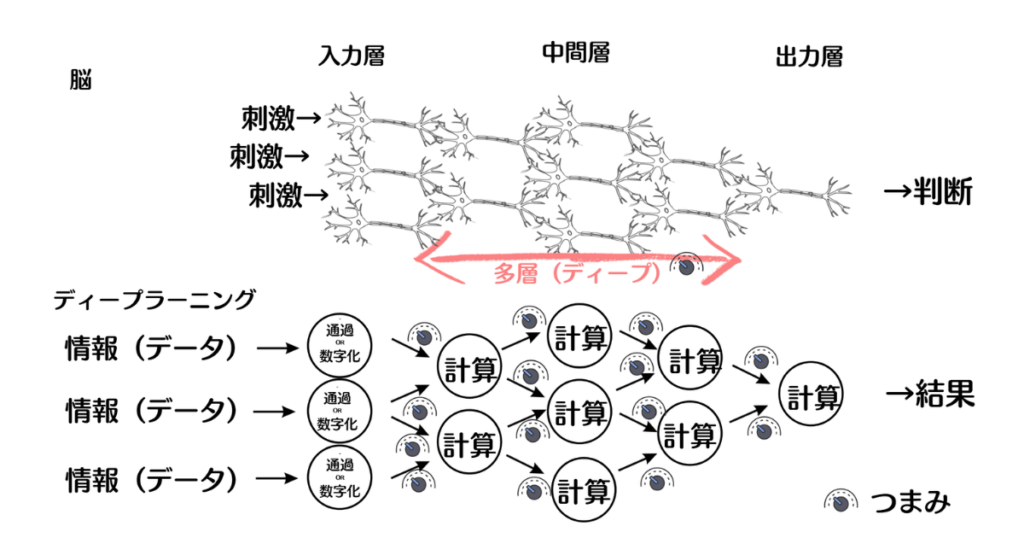
2. バッチ正規化とは?
バッチ正規化(Batch Normalization)は、偏った出力を整えて学習を安定化する処理です。
バッチ(Batch)とは、「まとめて処理する単位」です。
- ミニバッチ単位で平均と分散を計算
- 出力を「平均0・分散1」に標準化
- 必要に応じて、γ(拡大)とβ(移動)で元のスケールに調整
出力のばらつきを適切な範囲に整えることで、次の層が情報をしっかり学べる状態に戻します。
3. どこで整えるのか?
バッチ正規化は計算(活性化関数)の直前に行われます。
情報(データ) → 線(重み) → □(バッチ正規化) → ○(計算:活性化関数) → 出力
(次の層へ)
- 線:重みづけ(影響力)
- □:バッチ正規化(出力を整える装置) ⇒ モデル図には描かれてない部位
- ○:計算(活性化関数:非線形変換)
重みづけの結果が偏りそうなときに、整えてから活性化関数に渡すのがポイントです。
4. 偏ったら整えるとは?
例えば、重みづけの結果が全部「8〜10」に偏っていたら:
- モデルが「似たような反応しかしない」状態
- 次の層が受け取る情報に差がなく、学習が進みにくい
そこでバッチ正規化は:
- ミニバッチ単位で平均μと分散σ²を計算
- 出力を「平均0・分散1」に整える(標準化)
- γ(スケーリング)とβ(シフト)で必要なら元に戻す(学習可能なパラメータ)
「偏ったら整える」=「ばらつきを復活させて、学習できる状態に戻す」というイメージです。
5. なぜばらつきが必要なのか?
機械学習は「違いを学ぶ」ことで成長します。
- 出力が全部似ていると、違いが見えず、学習が止まる
- ばらつきがあると、モデルは「どこが違うか」を学べる
「ばらつき=情報の濃淡」こそが、学習の燃料です。
6. 推論時の注意点
- 学習時はミニバッチごとに平均・分散を計算
- 推論時は学習時に蓄積した平均・分散を使用
- これを忘れると推論結果が大きくぶれる原因になる
7. RNNや時系列モデルとの相性
バッチ正規化は「バッチ単位で統計を取る」ため、RNNなど時系列モデルでは使いにくいことがあります。
代替手法:
- Layer Normalization:層単位で正規化
- Instance Normalization:画像処理などで使用
モデルの構造に応じて、正規化手法を使い分ける必要があります。
まとめ
- 層が深くなると出力のばらつきが大きくなる
- バッチ正規化はミニバッチ単位で整えて学習を安定化
出力が偏ったら整える──それがバッチ正規化の役割です。
📘 シリーズ記事の流れ
次の記事 ▶️:
【DS検定対策15】データベース3種の違いと使い分け
DS検定で頻出のデータベース3種(データレイク・DWH・データマート)を図と比喩でわかりやすく整理。用途や違いを直感的に理解できます。
i-noma.com
2025.11.19
【DS検定対策13】バギングとブースティングの仕組みと違い|分散と精度を安定化
DS検定対策。バギング(Bagging)とブースティング(Boosting)の仕組み、違い、代表的なアルゴリズム(ランダムフォレスト、AdaBoost、Gradient Boosting、XGBoostなど)をわかりやすく解説。モデルの安定化や精度向上の考え方も整理。
i-noma.com
2026.01.21
📚 シリーズトップ:

DS検定対策シリーズ完全ガイド|全21記事で合格を目指す【目指せDi-Lite】
DS検定(データサイエンティスト検定リテラシーレベル)の合格を目指す全21記事の完全ガイド。数学・統計・機械学習を初心者向けに図解とLaTeX数式でわかりやすく解説。3回受験の失敗談から学ぶ効果的な勉強法・過学習対策も公開。Di-Lite認定(DX推進パスポート)取得を応援します。
i-noma.com
2026.01.13

コメント