

ディープラーニングというと、「AIが自動で学習してくれる便利な技術」と思いがちです。しかし実際のAI開発で一番大変なのは「モデル作成」ではなくデータ準備で、これが非常に手間がかかります。
人間も勉強するには知識や経験が必要ですが、AIも大量のデータを食べて初めて賢くなります。情報が少なかったり、間違った知識を与えられたりすれば正しく学習できません。AIも全く同じなんですね。まさに人工知能 Artificial Intelligence です。
本記事では、AI開発におけるデータ準備の重要性と、その具体的なステップを紹介します。
1. 良質なデータがなければ学習できない
ディープラーニングにおけるデータは「教材」にあたります。
- データが少ないと → 学習が進まず、AIが賢くならない
- データが偏っていると → 特定のパターンに過剰反応して誤った判断をする
- データが間違っていると → 間違った答えを覚えてしまう
たとえば「犬と猫を判定するAI」を作ろうとした場合、犬の画像ばかりが集まって猫が少ないと、AIは「ほとんど犬と答えるAI」になってしまいます。
つまりデータの質と量こそがAI開発の成否を左右する最大の要因なのです。
2. データ収集の方法
AIに学習させるためのデータは、以下のような方法で集められます。
- 既存の公開データセットを利用
例:犬猫画像データセット、株価や天気などのオープンデータ - 企業が自社で収集
例:製造ラインの不良品データ、顧客アンケート、センサー情報 - クラウドソーシングで収集
景品や謝礼をつけてアンケートを実施し、データを得る
「なぜ無料で体験できたり、商品をもらえたりするの?」と思うことがありますが、データ収集のニーズ で使われているかもですね。AI開発に使える良質なデータは、お金を払ってでも手に入れたい貴重な材料となるわけです。
3. データ前処理 ― AIが学習できる形に整える
集めたデータはそのままでは使えません。AIが処理しやすい形に整える作業が必要です。
欠損値の処理
- データが一部抜けている場合は「補完」するか「除外」する
- 例:年齢のデータが抜けている → 平均値で補う
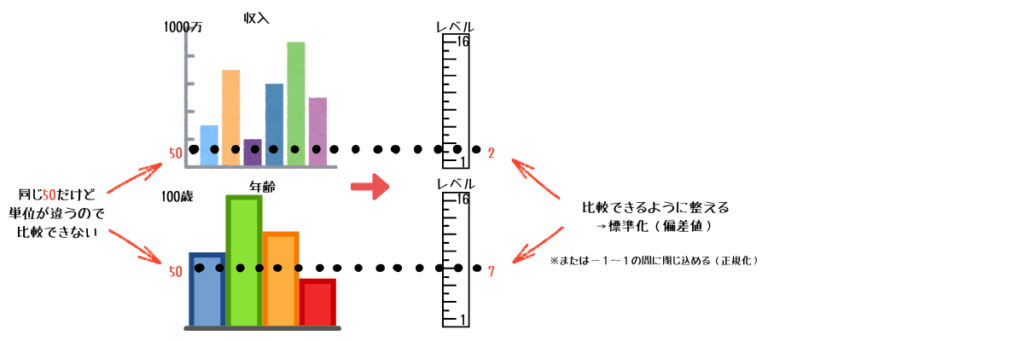
正規化・標準化
- 単位やスケールが異なる数値を比較できるように揃える
- 例:年齢(0~100)と収入(0~1,000万)を同じ基準(レベル1~16とか)に変換
カテゴリデータの変換
- 「男」「女」のような文字情報を数値に変換する
- 例:男=1、女=2 といった符号化
こうした作業をまとめて「データ前処理」と呼びます。面倒ですが、この工程が疎かだといくら優れたアルゴリズムを使っても良い結果は出ません。
4. ラベル付け ― 教師データの鍵
画像認識AIを作るときには、膨大な画像に対して「これは犬」「これは猫」といった正解ラベルをつける必要があります。これをラベリングと呼びます。
- 犬と猫の写真を数千枚集め、それぞれに正解ラベルを付与
- 病気診断AIなら、X線画像に「良性」「悪性」のラベルを医師が付与
この地道なラベル付け作業が、AIの「教師データ」として機能します。まさに「先生の赤ペン」みたいな役割を果たすのですね。
5. データ準備はAIの「9割」
AI開発において「モデル設計が1割、データ準備が9割」とも言われます。
理由はシンプルで、データが整っていなければいくら高度なアルゴリズムを組んでも正確に学習できないからです。
良質なデータを大量に準備し、適切に前処理・ラベリングすること。これこそがディープラーニング成功のカギなのですね。
まとめ
ディープラーニングは魔法の箱ではなく、データを与えて初めて学習できる存在です。
- 良質で偏りのないデータを集める
- 欠損値やスケールを調整して前処理する
- 教師データとしてラベルを付ける
この地道な作業こそがAIを支えています。
次回は、AIがどのようにして「誤差を最小化」し、学習を進めていくのかを解説します。人間の数学の知識(特に微分!)がどのようにAIに活かされているのかも紹介します。
関連記事(シリーズ)
- 【DL超入門1】ディープラーニングとは?初心者でもわかるAIの基本と仕組み
- 【DL超入門2】ディープラーニングの学習方法 ― 回帰・分類・強化学習をわかりやすく解説
- 【DL超入門3】AI開発のカギはデータ準備 ― 良質なデータがディープラーニングを支える
- 【DL超入門4】AIが学習する仕組み ― 誤差最小化と過学習の問題をわかりやすく解説
- 【DL超入門5】「自然言語処理」ってなに?
- 【DL超入門6】ChatGPTってなに?
- 【DL超入門7】画像を処理するということは?CNNとGANのしくみをやさしく解説
- 【DL超入門8】動画(時系列データ)の扱い方 ― RNN(再帰型ニューラルネットワーク)とは?
(補足)この記事で扱ったキーワード(G検定シラバスベース)
特徴量, ラベル付け, 前処理, 欠損値補完, 正規化, 標準化, ワンホットエンコーディング, データ拡張, バリデーションデータ, ホールドアウト法

コメント