

データ分析とは?
データ分析とは、データを収集・整理・解析してパターンや傾向を見つけ出すプロセスです。
AIは「万能で、命令文を入力すれば答えを出してくれる」と思われがちですが、実際には 予測には必ずデータが必要 です。
例えば、犬と猫を判別するAIを作る場合、膨大な犬と猫の画像データが必要になります。
- 犬の画像には「犬」という正解ラベル
- 猫の画像には「猫」という正解ラベル
このように正解情報を与えて学習させる手法を 教師あり学習 と呼びます。
一方で、正解ラベルがなくても特徴を見つけてグループ分けできる 教師なし学習 という手法もあります。例えば「犬グループ」と「猫グループ」に分けることは可能ですが、ラベルを与えない限り「犬」「猫」という名前を付けることはできません。
また、過去の数値データ(気温や価格など)から未来を予測することもデータ分析の一例です。ネット通販やWebサイトでは、購入履歴やアクセス履歴をもとに「おすすめ商品」を提示する仕組みも広く使われています。
データ分析に使われるプログラミング言語
データ分析で最もよく使われる言語は Python(パイソン) です。Pythonは汎用性が高く、直感的に書けるため初心者にも扱いやすい言語です。
代表的な手法には以下があります。
- 回帰分析
- 分類
- ディープラーニング
- ロジスティック回帰、決定木、サポートベクターマシン(SVM)など
Pythonでは、モデルを指定してパラメータを設定するだけで、これらの手法を比較的簡単に実装できます。
import numpy as np # 数値計算を行うNumpyライブラリを読み出している
from sklearn.linear_model import LinearRegression # 回帰分析モデルを読み出している
# 説明用の入力データ(X)と答えとなる出力データ(y)を用意
X = np.array([[1], [2], [3], [4], [5]]) # 入力(例:1〜5)
y = np.array([2, 4, 6, 8, 10]) # 出力(例:2の倍数)
# モデルとして 回帰分析モデルを指定
model = LinearRegression()
# モデルにデータを学習させる(実行する)
model.fit(X, y)
# 学習したモデルを使って予測を実行する
print("予測結果:", model.predict([[6]])) # 入力6に対する予測値を表示Pythonの基本ライブラリ
Pythonの基本ライブラリ
データ分析を始めるときに、まず覚えておくと便利な道具が3つあります。
NumPy(ナンパイ)
たくさんの数字をまとめて計算できる道具です。普通なら一つずつ計算するところを、まとめて一気に足したり掛けたりできます。
Pandas(パンダス)
表のように行と列があるデータを扱う道具です。Excelの表をイメージすると分かりやすく、データを読み込んだり並べ替えたりできます。
Matplotlib(マットプロットリブ)
データをグラフにして見やすくする道具です。最終的な結果を見せるときだけでなく、途中の確認にもよく使われます。
まずはこの3つを使えるようになれば、データ分析の第一歩を踏み出せます。
データ分析の流れ
実際のデータ分析では、データ整理と前処理(クレンジング) が大部分を占めます。
- 欠損値の除去や補完
- 重複データの処理
- 単位の統一
これらを整えたうえで、可視化や解析を進めます。データはExcelの表形式をイメージすると理解しやすいでしょう。
実践環境:Jupyter NotebookとGoogle Colab
プログラミング環境としては、無料で高性能な Jupyter Notebook がよく使われます。
さらに手軽に試すなら、Google Colab がおすすめです。Googleアカウントさえあれば、ソフトをインストールせずにWebブラウザ上でPythonを実行できます。試しに、Google Colab のリンクで
をクリックして 下記のようにコピペして 実行させてみてください。
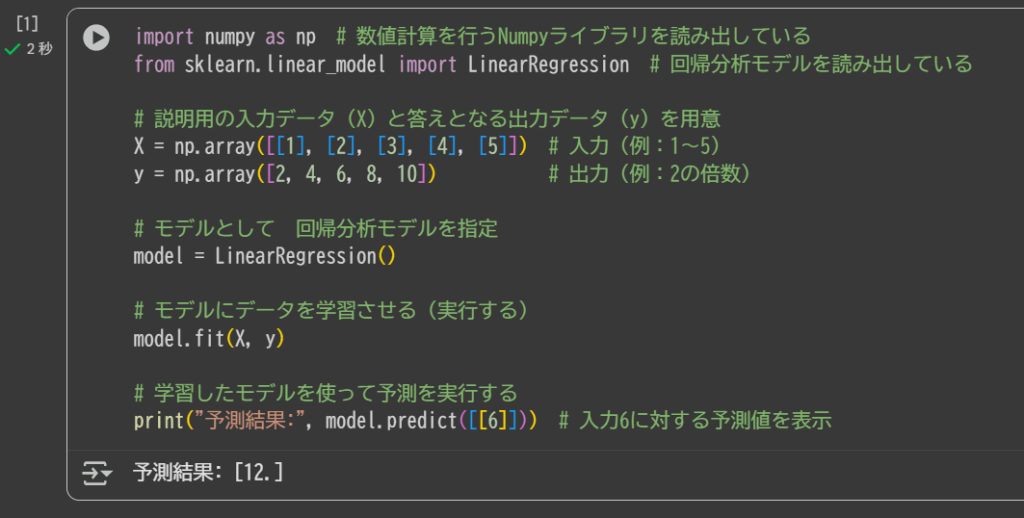
下記のボタンが実行です。

xが1増えるの対してyが2増える(x=2y)のモデルで入力6の時を予測しているので、結果が12 と出ています。
Colabを立ち上げてサンプルコードをセル単位で実行すれば、すぐに「データ分析の手触り」を実感できるでしょう。
生成AIとデータ分析
最近では、生成AIを活用してPythonコードを自動生成 することも可能です。
- 作りたいAIをプロンプトで指示
- 生成されたコードをColabにコピペ
- ワンクリックで実行・可視化
ただし、生成AIが出力したコードはエラーになることも多く、修正を繰り返す必要があります。これは逆に「ソフトウェア開発の醍醐味」とも言えます。
データ分析の楽しみ方
データ分析を進めると、途中の可視化や解析から 新しい課題や気づき が生まれます。それを深掘りしたり発展させていくことが、データ分析の大きな魅力です。
モデル選択の注意点
ディープラーニングは「万能の神」のように思えるかもしれませんが、必ずしも最適解ではありません。
- 課題がシンプルな場合は、回帰モデルの方が高精度になることもある
- データの複雑性やモデルのチューニング次第で、ディープラーニングが期待外れの結果になることもある
重要なのは、前処理を丁寧に行い、相関関係を分析し、仮説を立てたうえで適切なモデルを選ぶこと です。
まとめ
- データ分析は「収集 → 整理 → 解析 → 可視化 → 仮説検証」のプロセス
- Pythonと基本ライブラリ(NumPy / Pandas / Matplotlib)が基礎
- 実践環境はGoogle Colabが手軽でおすすめ
- 生成AIは便利だが、エラー修正を繰り返す過程も学びの一部
- モデルは課題に応じて選択することが重要
データ分析は、単なる技術ではなく 「気づきを得るための探究プロセス」 です。生成AIを壁打ち相手にしながら、ぜひ実践を通じて楽しんでみてください。


コメント