

自然言語処理と聞くとChatGPTを思い浮かべますよね。ChatGPTは正確にいうと「大規模自然言語処理(LLM)」であり、自然言語処理の応用形です。ここで扱うのはもっと基本的な仕組みで、入力(Input)を“人間の言葉のまま処理する”という考え方です。
イメージは「アレクサ!僕の好きな音楽をかけて~~」のように、曖昧な言葉でも要点を理解して動く仕組みです。言葉の揺れや曖昧さを数学的に扱うための技術が自然言語処理(NLP)となります。
1. 自然言語処理とは?
NLP(Natural Language Processing)は、人間が日常で使う自然言語(日本語・英語など)をコンピュータが理解・生成できるようにする技術です。言葉は曖昧で多義的なため、単純なルール処理では扱えません。そこで、言語学・統計・機械学習を組み合わせて“言葉を数理的に扱う”仕組みが作られています。
- 前処理(クレンジング・正規化)
- 形態素解析(単語分割+品詞付け)
- 係り受け解析(文構造の把握)
- 特徴抽出(不要語の削除など)
- タスク実行(翻訳・感情分析・質問応答など)
- 評価(GLUEなどのベンチマーク)
2. 前処理:クレンジングと正規化
テキストデータには、HTMLタグ・記号・改行コードなどのノイズが多く含まれています。これを整理するのが前処理です。英語では大文字小文字、日本語では全角半角の統一などを行い、“純粋な言語情報”に整えます。
→ クレンジングは「テキストをきれいに整える」工程です。(お掃除のクレンザーのイメージ)
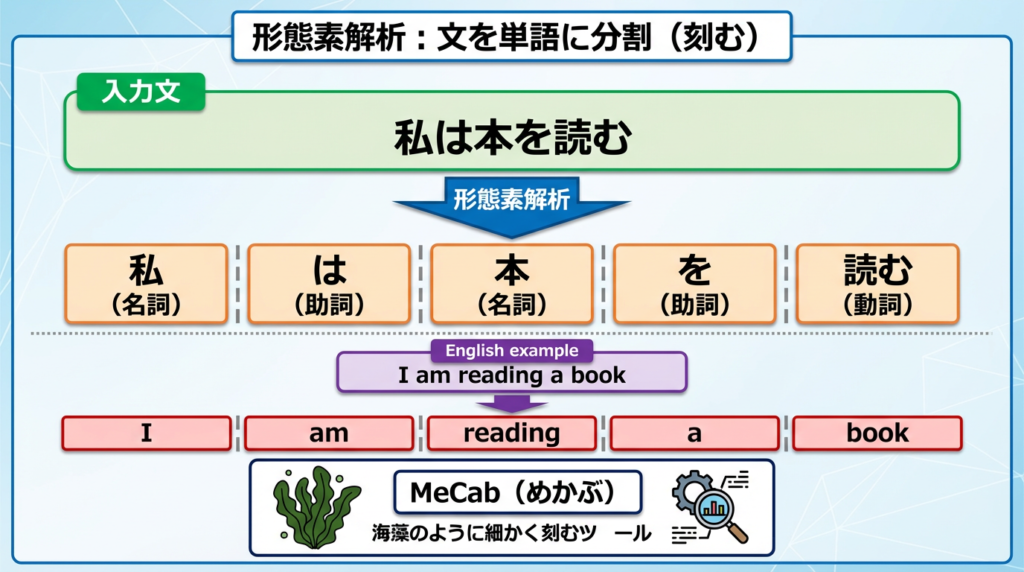
3. 形態素解析:文を“刻む”
日本語は英語のように単語の間にスペースがないため、まず「どこで単語が切れるか」を決めます。これが形態素解析です。
代表的なツール:
・MeCab(めきゃぶ) … 高速・定番 細かく刻む海藻(めかぶ)
・JUMAN(じゅまん) … 研究用途で定評 呪文(じゅまん)のように分解
・ChaSen(ちゃせん) … 古くからある解析器 茶筅(ちゃせん)で細かくする
例:「私は本を読む」 → 「私/は/本/を/読む」 → 文を“刻む”工程。
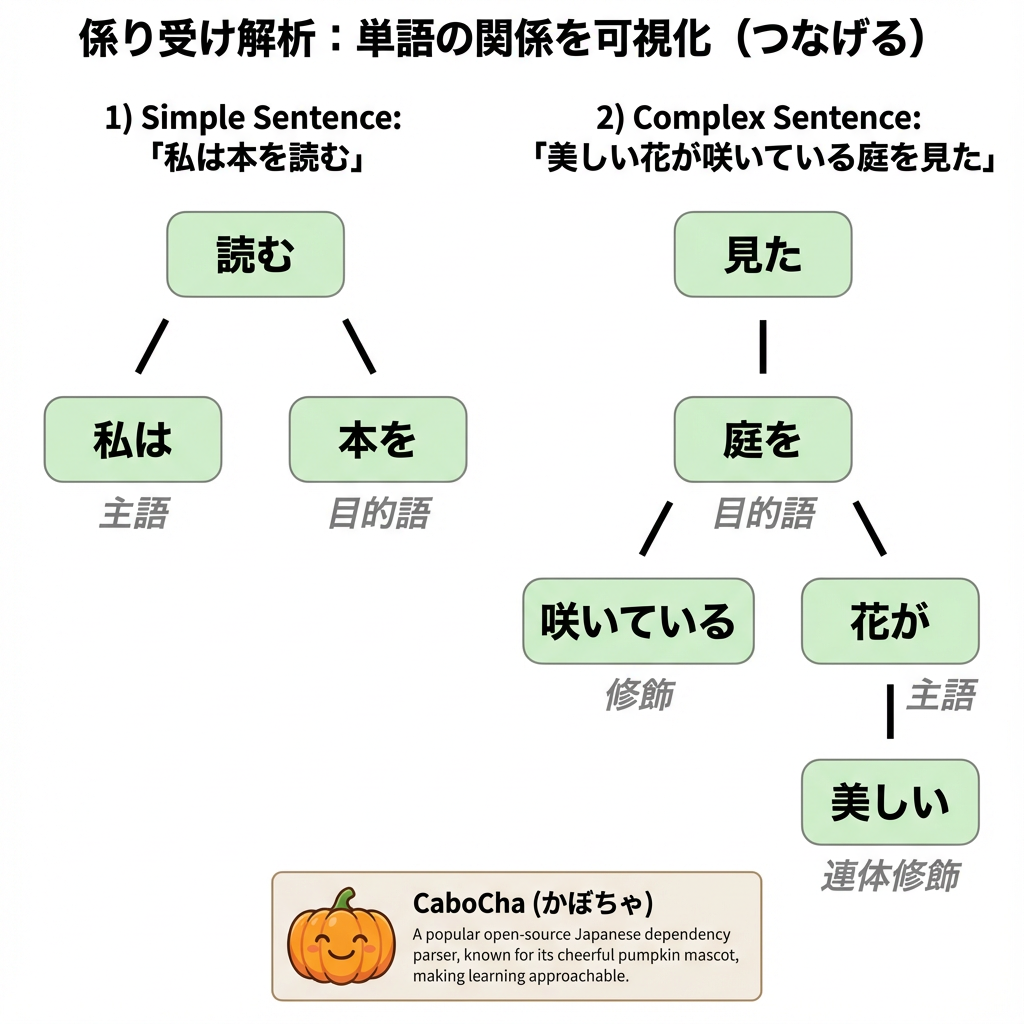
4. 係り受け解析:文を“つなげる”
単語を切っただけでは意味はつかめません。「誰が」「何をした」の関係を整理するのが係り受け解析です。
代表的なツール:
・CaboCha(かぼちゃ) … MeCabと組み合わせる定番 かぼちゃのような塊
・KNP … JUMANと組み合わせる構文解析器 キンパのようにまとめる
・GiNZA(ぎんざ) … spaCyベース、形態素+係り受け統合 銀座=路地がつながる街
例:「私は本を読む」 → 「私 → 読む」「本を → 読む」 → 文を“つなげる”工程。
5. 特徴抽出:意味のある部分を残す
解析後の単語の中には「は」「が」「the」「of」など、頻出だが意味を持たない語があります。これらを除去するのがストップワード処理です。また、動詞の形を統一するステミングも行います。
例:running/ran/runs → run(語幹に統一)
→ “枝葉を落として幹を残す”工程です。
6. 固有表現抽出(NER):名前を抜き出す
文中から「人名・地名・組織名・日付」などを見つける処理をNER(Named Entity Recognition)といいます。
例:「トヨタは名古屋に本社を置く」 → 「トヨタ=組織」「名古屋=地名」
ニュース記事の情報整理や検索エンジンなどにも使われているそうです。
7. 評価:GLUEベンチマーク
モデルの「言語理解力」を評価するのがGLUEベンチマークです。感情分析(SST-2)や文の意味比較(MRPC)など9種類のタスクで総合的に評価します。
→ 「自然言語処理の全国模試」のような位置づけです。
8. GLUEとNERの違い
- NER:特定タスク(情報を抜き出す)→「国語の一教科」
- GLUE:モデル全体の実力を測るベンチマーク→「全国模試」
GLUEの説明の中に他のタスクが混じってないかを問われる問題。説明文があっていると見抜くの難しいですよね。GLUEは基本的に文または文ペアを入力として、出力が一つ
代名詞は何を指している? → Yes/No(1つ)
ポジティブかネガティブか? → どちらか(1つ)
矛盾があるかないか? → 含意/矛盾/中立(1つ)
です。
そうではない選択肢(例えばNERのように固有名詞をすべて取り出すタスクとか)は不適切と見分けましょう。説明文自体は正しくても、そのタスクがGLUEに含まれるかは別問題なので注意が必要です。
9. 自然言語処理の応用例
- 検索エンジン(形態素解析+ストップワード除去)
- 機械翻訳(係り受け解析+意味理解)
- 音声認識(文字化後にNLP処理)
- 感情分析(SST-2型タスク)
- 質問応答(QNLI型タスク)
- チャットボット(NLPの総合応用)
10. まとめ
自然言語処理は「言葉を分けて、つなげて、要点を抜き出す」技術です。
- クレンジング:きれいに整える
- 形態素解析:刻む
- 係り受け解析:つなげる
- 特徴抽出: ストップワード=不要な語を削除 ステミング=枝葉を落として幹にする
- NER:情報を抜き出す
- GLUE:総合力を試す全国模試
📘 シリーズ記事の流れ
次の記事 ▶️:
📚 シリーズトップ:


コメント