

本記事では、DS検定の出題範囲に含まれるが、個別章で扱わなかった重要項目をまとめて解説します。いずれも頻出・応用可能な知識ですので、理解と記憶の定着を意識して整理しましょう。
指数と対数
- 指数関数: y = a^x の形で、xが増えるとyは爆発的に増加(指数的増加)。
- 対数スケール: 指数関数の急激な増加を視覚的に直線化するため、y軸の目盛りを指数的に圧縮。
- 対数関数: y = log x。ゆっくり増加し、指数スケール上では直線的(変動を均一)に見える。
- 逆関係: 指数と対数は互いに逆関係。軸のスケールを変えるとグラフ形状が入れ替わる。
実験計画法
統計的手法により、推定誤差を最小化しつつ因果関係や効果を効率的に検証する枠組み。
| 用語 | 意味・役割 | 実験設計での位置づけ |
|---|---|---|
| 実験群 | 新薬や処置を与えるグループ | 効果を検証する対象 |
| 対照群 | 処置を与えない、または偽薬を与えるグループ | 比較の基準 |
| 被験者群 | 実験に参加する人たち全体 | グループ分けの前段階 |
| ランダム化 | 偏りなく公平にグループ分けする手法 | 実験群と対照群への分け方の方法 |
推定誤差の種類
- 偶然誤差: 自然なばらつき。毎回異なる。
- 系統誤差: 測定方法や環境に依存。偏りが一方向。
抽出法
| 抽出法 | 説明 | 使われる場面・特徴 |
|---|---|---|
| 単純無作為抽出 | 母集団から完全にランダムに抽出 | 最も基本的。偏りがない 母集団リストが必要 |
| 層別抽出法 | 母集団を属性ごとにグループ(層)に分けて、それぞれからランダムに抽出 | 地域・年齢・性別などのバランスを保ちたいとき |
| 集落抽出法 | 母集団を小さなグループ(集落)に分けて、いくつかの集落をランダムに選び、その中の全員または一部を調査 | 地理的に分散した調査 (例:学校単位、町単位) |
| 多段抽出法 | 抽出を複数の段階で行う。例:まず市区町村を選び、次に世帯を選び、最後に個人を選ぶ | 大規模調査でコストや手間を抑えたいとき |
| 系統抽出法 | 一定の間隔でサンプルを抽出(例:名簿から10人おきに選ぶ) | 名簿やリストがあるときに簡便に使える |
フィッシャーの三原則
- 反復: 同条件で複数回実施し、偶然誤差を平均化。
- 無作為化: 順序や割り当てを無作為(ランダム)に。
- 局所管理: 外的要因をブロックし、誤差の影響を排除。
ランダムに割り当てる( 無作為化)+何度も測る ( 反復)+環境差を抑える ( 局所管理)
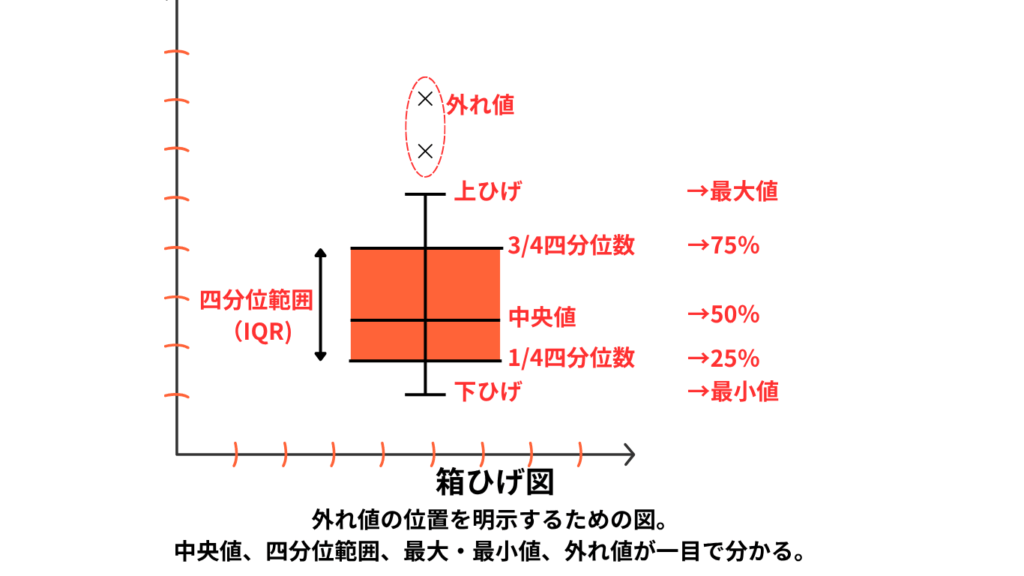
箱ひげ図(Boxplot)
分散学習と連合学習
| 学習方式 | 分散の単位 | 特徴・用途 |
|---|---|---|
| データ並列学習 | データ | 同じモデルで異なるデータを並列処理 |
| モデル並列学習 | モデル構造 | 巨大モデルを分割して学習 |
| 分散並列学習 | データ+モデル | 両方を分散、超大規模に対応 |
| 連合学習 | 端末ごとのデータ | プライバシー重視の協調学習 |
| 蒸留型連合学習 | 小型モデル+知識 | 通信量削減と端末負荷軽減 |
Dockerとコンテナ技術
異なるOSでも同一の開発環境を再現可能。DockerはLinuxカーネルの機能を活用し、軽量な仮想環境(コンテナ)を構築。必要なライブラリや設定をパッケージ化し、開発から運用までの環境差異による問題を削減。再現性と保守性を向上。
・アプリケーションと依存関係→Dockerイメージ にパッケージ化
・ローカル環境を本番環境にDockerファイルでデプロイ(再現)
Dockerは「環境をまるごと箱に詰めて、どこでも同じように動かせる技術」。その箱がDockerイメージで、動かすとコンテナになる。
RESTとSOAP、データ形式の比較
通信方式の比較
| 項目 | REST API | SOAP API |
|---|---|---|
| データ形式 | JSON(扱いやすく軽い), XMLなど | XMLのみ |
| 通信方法 | HTTP中心 | HTTP, SMTPなど |
| 柔軟性 | 高い | 低め(厳格) |
| セキュリティ | 標準的 | 高度な機能あり |
| 利用場面 | Web・モバイル リアルタイム性あり | 金融・業務システム 古いプロトコル |
REST APIのHTTPメソッド一覧
| メソッド | 用途 | 動作内容 | 代表的な使用例 |
|---|---|---|---|
| GET | データ 取得 | サーバーからリソースを取得する | 商品一覧の取得、ユーザー情報の参照 |
| POST | データ 作成 | 新しいリクエストやリソースを送信する | 顧客データを送信して予測結果を得る |
| PUT | データ 更新 | 既存リソースを完全に置き換える | プロフィール情報の更新など |
| PATCH | 部分更新 | リソースの一部だけを更新する | 一部フィールドだけ変更したいとき |
| DELETE | データ 削除 | 指定リソースを削除する | 商品データの削除、アカウント削除など |
データ形式の比較
| 形式 | 区切り | 構造 | 可読性 | 主な用途 |
|---|---|---|---|---|
| CSV | カンマ | 単純(1行=1レコード) | ◎ | 表形式データ (Excelなど) |
| TSV | タブ | 単純(カンマを含むデータに強い) | ◎ | カンマを含む表形式に便利 |
| XML | タグ | 階層あり(構造は柔軟だが冗長) | △ | SOAP通信、業務データ |
| JSON | キーと値 | 階層あり (ネスト構造によりCSV変換が複雑) | ◎ | REST API、 Webサービス |
バックアップの覚え方
- 差分: フルバックアップの「サブ」分 → 一つのファイル
- 増分: 象(増)のように一歩ずつ → 変更があるたび複数ファイル
不偏分散
分散とはばらつきのことで、ばらつきとは平均との差のこと。平均との差はプラス側とマイナス側があるので、2乗することで、大きさだけ維持しつつ 正も負も 正の数にする。
誤差=(データー平均値) ※あとで2乗するのでどっちから引いても同じだけど
分散= 全データの 誤差² / サンプル数
で、サンプル数は 母分散は普通にデータ数にすればよいのですが 不偏分散はデータ数ー1 にしないといけません。これは不偏分散というのが標本から母分散を推定してるので数字が大きめに出がちで過小評価になりがち なのでその補正をするということらしいです。
いまいちモヤモヤする話ですが、不偏分散といわれたら データ数 で割っちゃうというひっかっけにかからないようしましょう。
コレログラム
時系列データの自己相関を可視化するツール。周期性、ランダム性、パターンの持続性などを把握可能。
弱定常性(ワイドセンス定常性)とは、時系列データの統計的性質が時間によらず一定であることを意味します。
- ① 期待値(平均)が一定: どの時点でも平均値が同じ。
- ② 分散が一定: データのばらつきが時間に依存しない。
- ③ 共分散が時間差(ラグ)のみに依存: 時刻ではなく、時間差 h のみによって相関が決まる。
例:今日と明日の気温の関係が、来週の月曜と火曜の関係と同じなら、時間差1日の相関が一定。
📘 シリーズ記事の流れ
次の記事 ▶️:
📚 シリーズトップ:


コメント