

説明はソースコード内のコメント文(#が頭についている文)に入れています。
ブロックごとにコピーして、Google Colaboratoryにペーストして 実行してみてください。
コードの内容はわからなくても、なんとなく動きは実感できると思います。
# ==============================
# 1. 必要なライブラリのインストール
# ==============================
# Prophetは標準ではインストールされていないため、事前にインストールが必要
# yfinance: Yahoo! Financeから株価データを取得するライブラリ
# prophet : Facebook(現Meta)が開発した時系列予測ライブラリ
# --quiet オプションでインストール時の出力を抑制
!pip install yfinance prophet japanize-matplotlib --quiet
# ==============================
# 2. ライブラリのインポート
# ==============================
import yfinance as yf # 株価データを取得するためのライブラリ
import pandas as pd # データの整形や集計に使うライブラリ
import matplotlib.pyplot as plt # グラフ描画用ライブラリ
import japanize_matplotlib # 日本語表示対応
from prophet import Prophet # Prophetモデル本体
from datetime import datetime # 日付や時間を扱うための標準ライブラリ
# ==============================
# 3. 株価データの取得
# ==============================
# 予測対象とする銘柄のティッカーシンボルを指定
# "AAPL" は Apple社の株式を意味する
ticker = "AAPL"
# 取得開始日を文字列で指定(YYYY-MM-DD形式)
start_date = "2018-01-01"
# 取得終了日を「今日」に設定
# datetime.today() で現在日時を取得し、strftimeで文字列に変換
end_date = datetime.today().strftime("%Y-%m-%d")
# yfinanceを使って株価データを取得
# interval="1d" で1日ごとのデータを取得
df = yf.download(ticker, start=start_date, end=end_date, interval="1d")
# ==============================
# 4. Prophet用にデータ整形
# ==============================
# Prophetは「ds」列(日付)と「y」列(予測対象値)が必須
# 今回は終値(Close)を予測対象にする
df_prophet = df.reset_index()[["Date", "Close"]] # インデックスを列に戻し、必要列だけ抽出
df_prophet.columns = ["ds", "y"] # 列名をProphet仕様に変更
# ==============================
# 5. Prophetモデルの作成と学習
# ==============================
# yearly_seasonality=True で年単位の季節性を考慮
# daily_seasonality=False で日単位の季節性は無効化(株価は日単位の周期性が弱いため)
model = Prophet(yearly_seasonality=True, daily_seasonality=False)
# fit() でモデルを学習させる
model.fit(df_prophet)
# ==============================
# 6. 未来データフレームの作成
# ==============================
# 予測終了日を2030年12月31日に設定
future_end = datetime(2030, 12, 31)
# 今日から予測終了日までの日数を計算
days_to_predict = (future_end - datetime.today()).days
# make_future_dataframe() で未来の日付を作成
# periods に予測したい日数を指定
# freq="D" で日単位のデータを生成
# 過去データも含めた日付のDataFrameが返る
future = model.make_future_dataframe(periods=days_to_predict, freq="D")
# ==============================
# 7. 予測の実行
# ==============================
# predict() に未来データフレームを渡すと予測結果が返る
# 返り値には予測値(yhat)、下限(yhat_lower)、上限(yhat_upper)などが含まれる
forecast = model.predict(future)
# ==============================
# 8. グラフ描画(ローマ字ラベル)
# ==============================
plt.figure(figsize=(12, 6)) # グラフサイズを指定(横12インチ×縦6インチ)
# 実績値(青線)
plt.plot(df_prophet["ds"], df_prophet["y"], label="実績値", color="blue")
# 予測値(赤線)
plt.plot(forecast["ds"], forecast["yhat"], label="予測値", color="red")
# 信頼区間(予測の上下限)をピンク色で塗りつぶし
plt.fill_between(forecast["ds"], forecast["yhat_lower"], forecast["yhat_upper"],
color="pink", alpha=0.3, label="予測範囲")
# グラフタイトルと軸ラベル
plt.title("株価予測: Apple (AAPL)", fontsize=16)
plt.xlabel("日付") # 横軸ラベル
plt.ylabel("株価 (USD)") # 縦軸ラベル
# 凡例とグリッド表示
plt.legend()
plt.grid(True)
# グラフを表示
plt.show()下記の予測グラフが出力されます。
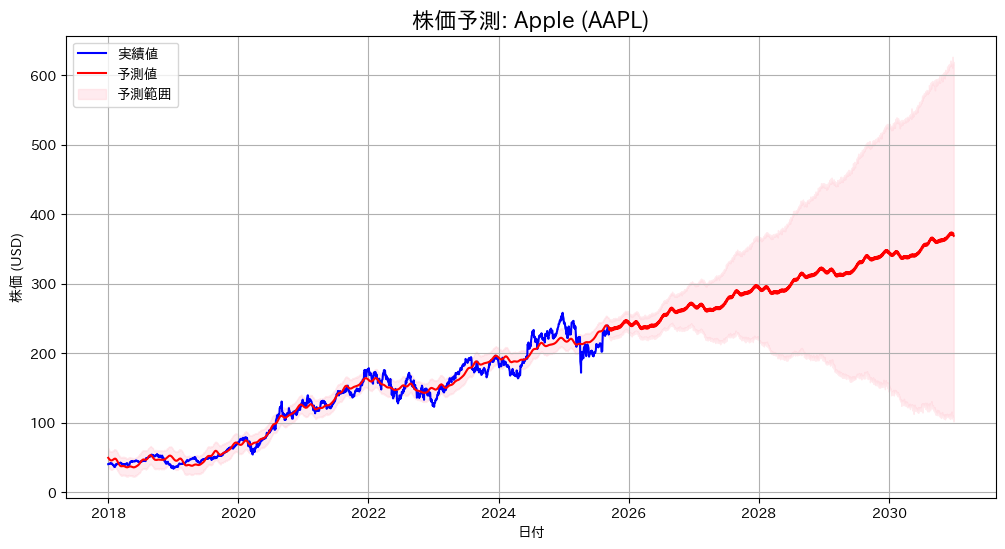
次は、財務指標が株価にどの程度影響するか、Lasso回帰を使ってみていきましょう。
from sklearn.linear_model import LassoCV
from sklearn.preprocessing import StandardScaler
import pandas as pd
# ===== 財務データ取得 =====
stock = yf.Ticker(ticker)
fin = stock.quarterly_financials.T
bs = stock.quarterly_balance_sheet.T
cf = stock.quarterly_cashflow.T
# インデックスのタイムゾーンを統一
for df_ in [fin, bs, cf]:
df_.index = df_.index.tz_localize(None)
# 株価を四半期末にリサンプリング
price_q = df["Close"].resample("QE").last().reset_index() # Reset index here
price_q = price_q.rename(columns={"AAPL": "Price"}) # Rename the 'AAPL' column to 'Price'
# 自己資本(Stockholders Equityがあれば使用)
if "Stockholders Equity" in bs.columns:
equity = bs["Stockholders Equity"]
else:
equity = bs["Total Assets"] - bs["Total Liabilities Net Minority Interest"]
# Resample financial data to quarterly frequency and forward fill
fin_q = fin.resample("QE").ffill()
bs_q = bs.resample("QE").ffill()
cf_q = cf.resample("QE").ffill()
equity_q = equity.resample("QE").ffill()
# ===== 指標計算(取得できない場合は除外) =====
metrics = {}
# Helper function to create a Series with the correct index
def create_metric_series(value, index):
if isinstance(value, pd.Series):
return value
elif isinstance(value, (int, float)):
return pd.Series(value, index=index)
return None
# PER
if "Net Income" in fin_q.columns and stock.info.get("sharesOutstanding"):
per_value = price_q.set_index("Date")["Price"] / (fin_q["Net Income"] / stock.info["sharesOutstanding"])
metrics["PER"] = create_metric_series(per_value, price_q["Date"]) # Use price_q["Date"] as index
# PBR
if stock.info.get("sharesOutstanding"):
pbr_value = price_q.set_index("Date")["Price"] / (equity_q / stock.info["sharesOutstanding"])
metrics["PBR"] = create_metric_series(pbr_value, price_q["Date"]) # Use price_q["Date"] as index
# ROE
if "Net Income" in fin_q.columns:
roe_value = fin_q["Net Income"] / equity_q
metrics["ROE"] = create_metric_series(roe_value, price_q["Date"]) # Use price_q["Date"] as index
# 配当利回り(HRM)
if stock.info.get("dividendYield") is not None:
hrm_value = stock.info["dividendYield"]
metrics["配当利回り"] = create_metric_series(hrm_value, price_q["Date"]) # Use price_q["Date"] as index
# 配当性向(HSK)
div_col = None
for c in cf_q.columns:
if "Dividend" in c:
div_col = c
break
if div_col and "Net Income" in fin_q.columns:
hsk_value = cf_q[div_col].abs() / fin_q["Net Income"]
metrics["配当性向"] = create_metric_series(hsk_value, price_q["Date"]) # Use price_q["Date"] as index
# 自己資本比率(JKS)
if "Total Assets" in bs_q.columns:
jks_value = equity_q / bs_q["Total Assets"]
metrics["自己資本比率"] = create_metric_series(jks_value, price_q["Date"]) # Use price_q["Date"] as index
# Remove None values from metrics dictionary
metrics = {k: v for k, v in metrics.items() if v is not None}
# Align metrics with price_q dates before concatenating
aligned_metrics = {}
for name, series in metrics.items():
aligned_metrics[name] = series.reindex(price_q["Date"], method='ffill')
# ===== DataFrame化 =====
df_metrics = pd.concat([price_q.set_index("Date")] + [v.rename(k) for k, v in aligned_metrics.items()], axis=1).dropna()
# ===== 回帰分析 =====
X = df_metrics.drop(columns="Price")
y = df_metrics["Price"]
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
lasso = LassoCV(cv=3, random_state=0)
lasso.fit(X_scaled, y)
coef_df = pd.DataFrame({
"Feature": X.columns,
"Coefficient": lasso.coef_
}).sort_values(by="Coefficient", key=abs, ascending=False)
# ===== 可視化 =====
plt.figure(figsize=(8,5))
plt.bar(coef_df["Feature"], coef_df["Coefficient"])
plt.axhline(0, color="black", linewidth=0.8)
plt.title(f"{ticker} 財務指標の株価への影響度(Lasso回帰)")
plt.ylabel("係数(標準化後)")
plt.show()
print(coef_df)ここで出力されるのは下記です。
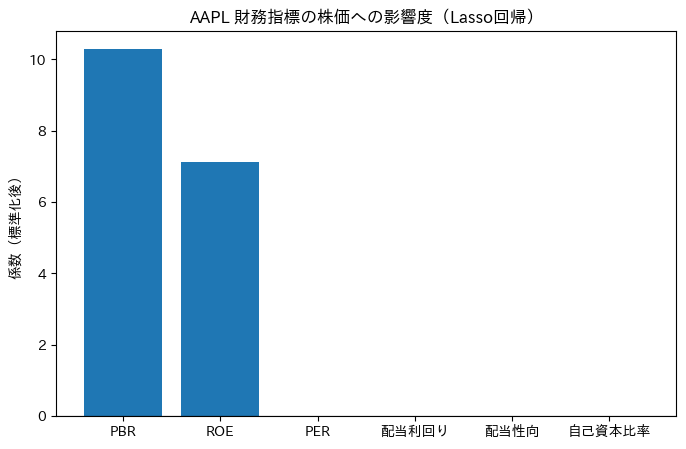
Feature Coefficient
1 PBR 10.281496
2 ROE 7.135837
0 PER -0.000000
3 配当利回り 0.000000
4 配当性向 -0.000000
5 自己資本比率 -0.000000
数字が大きさを表しています。
ディープラーニング(Lasso回帰)では重要ではない情報がゼロ化されてしまいました。なので、別の方法(ランダムフォレスト)で解析しSHAP値で可視化をしてみましょう
from sklearn.ensemble import RandomForestRegressor
import shap
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示対応
# ===== ランダムフォレスト回帰 =====
rf = RandomForestRegressor(
n_estimators=500,
random_state=0
)
rf.fit(X, y)
# 変数重要度(相対値)
importances = pd.Series(rf.feature_importances_, index=X.columns)
importances.sort_values().plot.barh()
plt.title("財務指標の重要度(ランダムフォレスト)")
plt.xlabel("重要度(相対値)")
plt.show()
# ===== SHAP値で影響度と方向性を可視化 =====
explainer = shap.Explainer(rf, X)
shap_values = explainer(X)
# 棒グラフ(平均絶対SHAP値)
shap.summary_plot(shap_values, X, plot_type="bar", show=False)
plt.title("財務指標の影響度(SHAP値)")
plt.show()
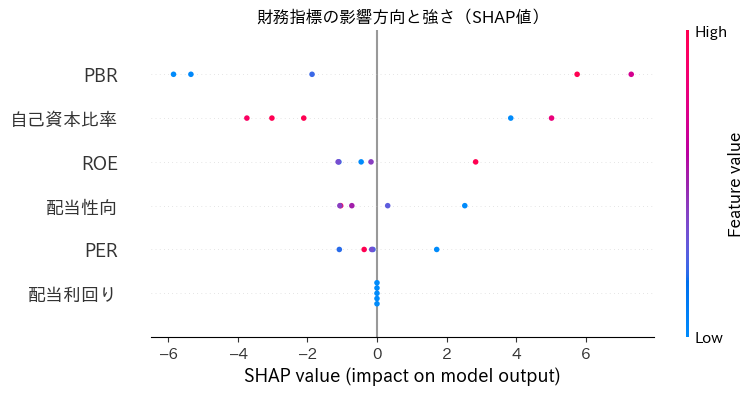
# 散布図(各特徴量の影響方向と強さ)
shap.summary_plot(shap_values, X, show=False)
plt.title("財務指標の影響方向と強さ(SHAP値)")
plt.show()
出力は下記です。考察等はリスキリング体験記|株価予測AI×財務分析|Aidemy成果物で学ぶPythonとProphet | cafe future blend の方を参照ください。
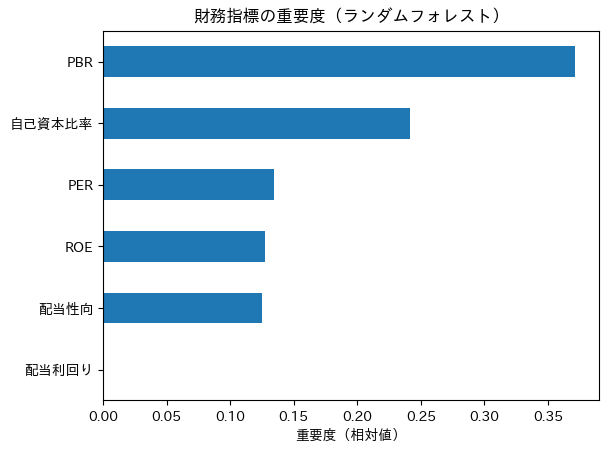
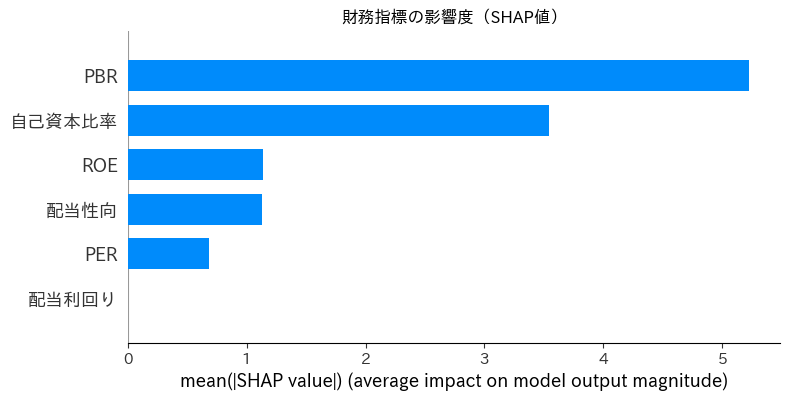
関連記事
・リスキリング体験記②|株価予測AI×財務分析|Aidemy成果物で学ぶPythonとProphet | cafe future blend
・退職後のリスキリング体験記①|専門実践教育訓練給付金×Aidemyでデータ分析を学ぶ | cafe future blend


コメント