

ディープラーニングの学習方法 ― 回帰・分類・強化学習をわかりやすく解説
前回の記事では、ディープラーニングの基本的な仕組みと「深い」と呼ばれる理由を整理してみました。今回はさらに踏み込んで、ディープラーニングがどのように学習するのかを考えていましょう。
学習方法の代表的なタイプは大きく3つです。
- 回帰:未来の数値を予測する
- 分類:ものをカテゴリーに分ける
- 強化学習:試行錯誤で最適な行動を学ぶ
1. 回帰 ― 未来を数値で予測する
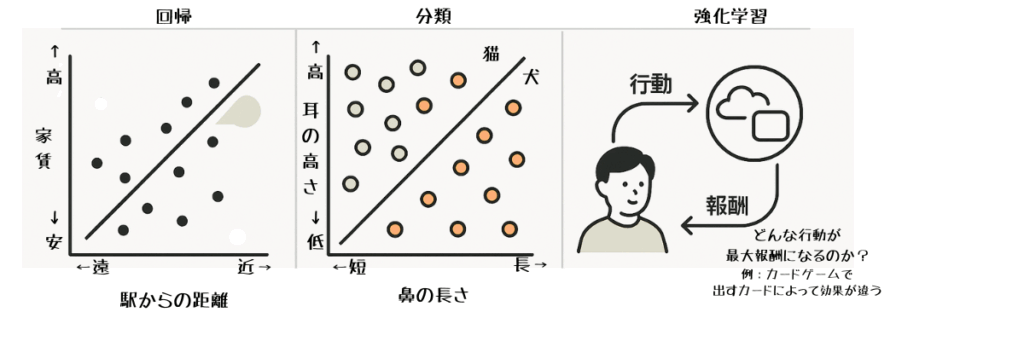
「回帰(Regression)」は、過去のデータから未来の数値を予測する方法です。
具体例
- 家賃の予測(駅からの距離・築年数・周辺の物価などをもとに算出)
- 株価や為替の推移予測
- 気温や需要の見込み
例えば「駅から徒歩5分以内なら家賃は高い傾向にある」といった相関をモデル化し、未来の物件情報を入力すれば家賃を予測できるのが回帰です。
ポイントは「数値の予測」に強い手法であること。
ただし、ペット可かどうかのように一見すると関連性が弱い要素が影響する場合もあり、そこを考慮できるのがディープラーニングの強みです。(特徴量、重みづけ)
2. 分類 ― 犬か猫かを見分ける
「分類(Classification)」は、与えられたデータをグループに分ける方法です。
具体例
- 犬と猫の画像を見分ける
- メールを「迷惑メール」「通常メール」に分ける
- 医療データから「良性腫瘍」「悪性腫瘍」を判別する
人間なら「犬には耳の形や鼻の特徴がある」と直感的に判断できますが、AIは大量の画像を学習し、「犬はこの特徴量、猫はこの特徴量」とルールを数値的に学習します。
分類は「Yes/No」や「どちらのグループか」を判断するのに強い手法です。
3. 強化学習 ― ゲームで勝つAI
3つ目の「強化学習(Reinforcement Learning)」は少し特殊です。これは、AIが自分で試行錯誤を繰り返し、報酬(ご褒美)を最大化する方法です。
具体例
- 囲碁や将棋で最適な一手を学ぶ
- ロボットが障害物を避けて移動する
- 自動運転車が安全に走行ルートを学ぶ
AIは「正解を与えられる」わけではなく、行動の結果として得られる報酬や失敗を通じて学習します。これによって人間でも難しい複雑な環境で成果を出すことが可能になります。
4. 3つの学習方法の違い
まとめると、それぞれの学習方法は次のように整理できます。
| 学習方法 | 得意分野 | 具体例 |
|---|---|---|
| 回帰 | 数値予測 | 家賃、株価、気温予測 |
| 分類 | グループ分け | 犬か猫か、迷惑メールか否か |
| 強化学習 | 最適行動の探索 | 囲碁AI、自動運転 |
この3つを組み合わせることで、多くの「予測」や「判断」が可能になります。
5.学習の要素を自分見つける
学習をするには「距離が近い遠い」とか「気温が高い低い」とか「耳の高さが高い低い」のように、予想するために使用するデータの要素が必要ですが、あらかじめわかっている場合はディープラーニングは不要です。
しかし、なんとなく距離が影響しそうだけどどれだけ重要なのかがわからないとか、気温が影響しているとは思わなかった!のような要素(特徴量)を自動的に見つけるなら、ディープラーニングの出番です。
特徴量の重要度を変化させながら、回帰、分類、強化学習を繰り返すことで回答の正解率が上がる(誤差が減る)ように調整していくのが、DLのやりかたです!
(ここは【DL超入門4】でもう少し詳しく取り上げています)
関連記事(シリーズ)
- 【DL超入門1】ディープラーニングとは?初心者でもわかるAIの基本と仕組み
- 【DL超入門2】ディープラーニングの学習方法 ― 回帰・分類・強化学習をわかりやすく解説
- 【DL超入門3】AI開発のカギはデータ準備 ― 良質なデータがディープラーニングを支える
- 【DL超入門4】AIが学習する仕組み ― 誤差最小化と過学習の問題をわかりやすく解説
- 【DL超入門5】「自然言語処理」ってなに?
- 【DL超入門6】ChatGPTってなに?
- 【DL超入門7】画像を処理するということは?CNNとGANのしくみをやさしく解説
- 【DL超入門8】動画(時系列データ)の扱い方 ― RNN(再帰型ニューラルネットワーク)とは?
(補足)この記事で扱ったキーワード(G検定シラバスベース)
教師あり学習, 教師なし学習, 強化学習, 回帰, 分類,
<強化学習>Q学習, マルコフ決定過程, 方策勾配法, Actor-Critic, 報酬

コメント