

これまでの記事では、ディープラーニングの基本や学習方法、そしてデータ準備の重要性についてシェアしてきました。今回は、いよいよ「AIがどうやって学習していくのか」を見ていきましょう。
AIは魔法のように答えを導いているのではなく、数学的に「誤差を減らす」ことを繰り返して成長しています。しかし、その過程には「過学習」という落とし穴もあります。
1. 誤差最小化 ― どんどん正確にしていく仕組み
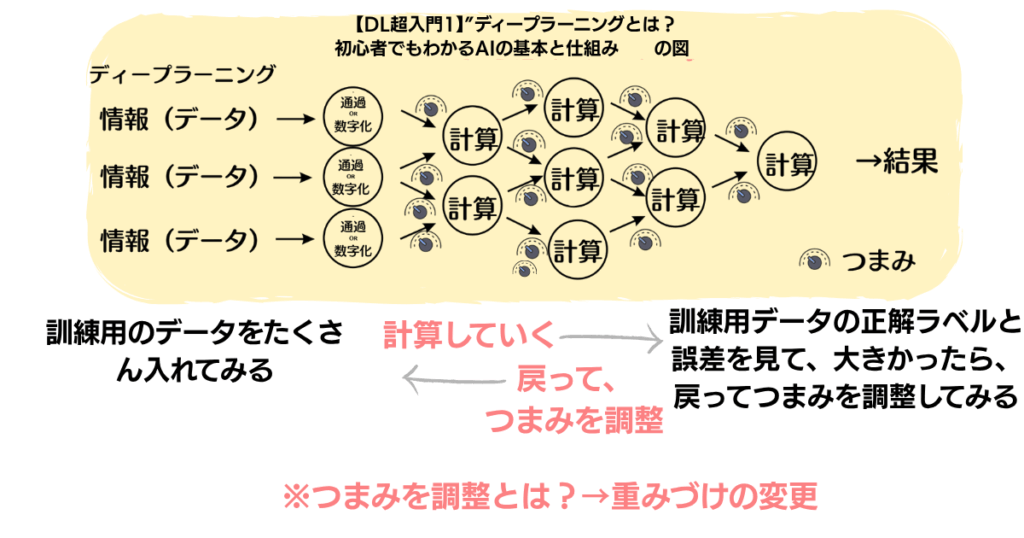
AIの学習は「予測」と「正解」を比べて、その差(誤差)をできるだけ小さくしていくプロセスです。
学習の流れ
- 予測をする
入力データ(例:画像)をもとにAIが答えを出す - 誤差を計算する
AIの答えと実際の正解を比較して「ズレ」を数値化する - 修正する
誤差を小さくするようにAI内部のパラメータ(重み)を調整する
この「予測 → 誤差計算 → 修正」を何度も繰り返すことで、AIは正解に近づいていきます。
2. 数学の裏側 ― 微分がAIを支えている
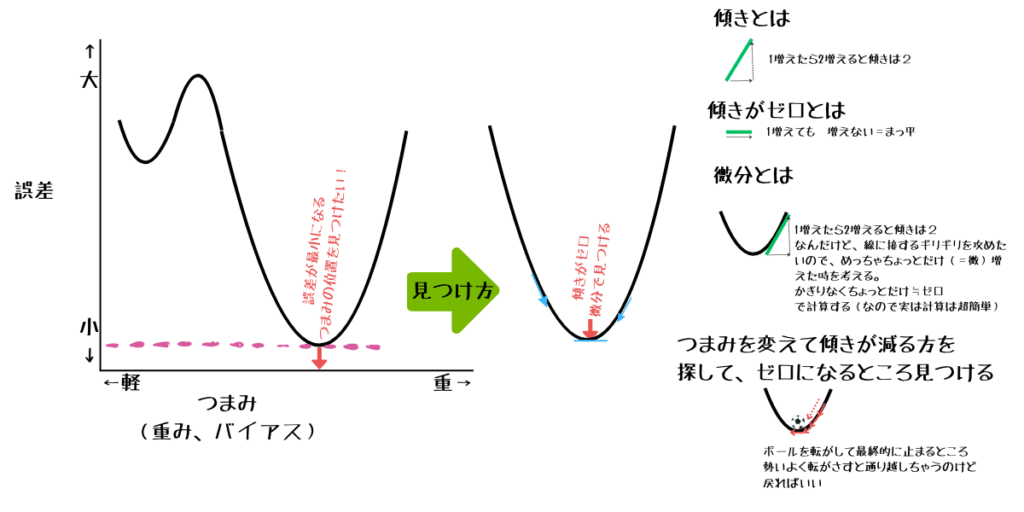
誤差を小さくするための調整は、実は高校数学で習う「微分」の考え方で行われています。
- 誤差関数(損失関数)という数式を用意する
- その関数を「微分」して、誤差が減る方向を計算する
- ほんの少しずつパラメータを動かし、誤差が最小になる点を探す
これは「最急降下法(Gradient Descent)」と呼ばれる手法です。イメージとしては、山の頂上からボールを転がして谷底(最小誤差地点)を探すようなものです。
AIが数学の力を借りて学習していることがわかりますね。
3. 過学習 ― AIの落とし穴
しかし、学習を進めすぎると別の問題が発生します。それが過学習(Overfitting)です。
過学習とは?
- 訓練データには完璧に対応できる
- でも新しいデータに弱く、実用で役に立たない
例えるなら、試験勉強で「過去問だけ丸暗記したけど応用問題が解けない」状態です。
AIも同じで、学習データに合わせすぎると「そのデータ専用の答えマシン」になってしまい、現実の未知データに対応できなくなります。
4. 過学習を防ぐ工夫(おまけ)
研究者たちは過学習を防ぐためにさまざまな工夫をしています。
データを増やす
学習データを大量に用意することで、偏りを減らし、より一般的なルールを学習できる。
正則化(Regularization)
学習しすぎて複雑にならないよう、AIの自由度に制約をかける。
ドロップアウト
学習中にランダムに一部のニューロンを無効化し、特定のルートだけに依存しないようにする。
検証データでチェック
訓練データ以外に「検証用データ」を使って、学習が進みすぎていないか常に確認する。
これらの工夫で、AIは「覚える」と「応用する」のバランスを取るように調整されています。
5. AI学習の本質 ― 誤差を減らし、一般化する力
まとめると、AIが学習する仕組みは次の通りです。
- 誤差を計算して最小化する(数学的な最急降下法)
- 過学習を避けるためにバランスを取る(正則化・ドロップアウトなど)
つまりAIの本質は「与えられたデータから規則性を学び、それを一般化する力」にあります。
まとめ
ディープラーニングは次のような仕組みで成り立っています。
- 誤差を最小化することで学習する
- 微分や最急降下法といった数学的手法を使う
- 過学習という落とし穴がある
- データの量や工夫で過学習を防ぐ
AIは万能ではなく、数学・データ・工夫の積み重ねで成り立っている技術です。
今回でディープラーニングの入門シリーズは一区切りですが、それぞれの要素の深堀解説や自然言語やデータサイエンスなどについても【超解説】していきたいともいます。
関連記事(シリーズ)
- 【DL超入門1】ディープラーニングとは?初心者でもわかるAIの基本と仕組み
- 【DL超入門2】ディープラーニングの学習方法 ― 回帰・分類・強化学習をわかりやすく解説
- 【DL超入門3】AI開発のカギはデータ準備 ― 良質なデータがディープラーニングを支える
- 【DL超入門4】AIが学習する仕組み ― 誤差最小化と過学習の問題をわかりやすく解説
- 【DL超入門5】「自然言語処理」ってなに?
- 【DL超入門6】ChatGPTってなに?
- 【DL超入門7】画像を処理するということは?CNNとGANのしくみをやさしく解説
- 【DL超入門8】動画(時系列データ)の扱い方 ― RNN(再帰型ニューラルネットワーク)とは?
(補足)この記事で扱ったキーワード(G検定シラバスベース)
損失関数, 誤差関数, 勾配降下法, 過学習, 汎化性能, バイアス・バリアンス, 正則化, ドロップアウト, 交差検証, エポック

コメント