

最近、「自然言語処理(NLP)」という言葉をよく見かけるようになりました。
AIとかチャットボットとか、便利なツールの裏側にある技術です。
でも、「自然言語」ってそもそも何?「処理」ってどういうこと?
今回は、シニアや初心者の方にもわかりやすく、やさしく説明してみたいと思います。
人の言葉をコンピューターがわかるようにする技術
ふだん、コンピューターは「命令文(プログラム)」で動いています。
でも、私たちが話す「日本語」や「会話文」は、命令文とはちがいますよね。
そこで、コンピューターが人の言葉を理解できるようにするのが「自然言語処理」です。
英語は分けやすい、日本語はむずかしい?
中学英語で最初に習った「This is a pen.」――覚えていますか?「これはペンです」って意味ですね。
英語は単語の間にスペースがあるので、「This」「is」「a」「pen」と簡単に分けられます。
でも、日本語はそうはいきません。
「これはペンです」は、ひらがなとカタカナがつながっていて、どこで区切るかがわかりにくい。
自然言語処理では、これを「これ」「は」「ペン」「です」といったように、意味のある単位に分けていきます。
この「分け方」がうまくできないと、コンピューターは文章の意味を正しく理解できません。
だから、日本語の処理は英語よりも少しむずかしいんですね。

言葉のつながりから意味を見つける
文章は、単語だけでなく「前後のつながり」が大事です。
たとえば「ペン」と「です」がセットになると、「これは何かを説明している文だな」とわかりますよね。
コンピューターも、こうした「言葉の並び方」から意味を見つけていきます。
このしくみがあるから、AIが文章を読んだり、質問に答えたりできるのです。
文字はどうやって数値になるの?
一般的に、コンピューターは「デジタル処理=数値化」というイメージがありますよね。
たとえば「アスキーコード」という仕組みでは、文字を1文字ずつ数字に変換できます。
でも、自然言語処理ではこの方法は使いません。
文字そのもののコードではなく、「その言葉がどれくらい出てくるか(出現頻度)」や「どの言葉と一緒に使われるか(つながり)」を数値化するのです。
この考え方が、意味を理解するための第一歩になります。
単なる文字の羅列ではなく、「意味のあるパターン」として扱うところが、自然言語処理の面白いところです。
よく出てくる言葉は、あまり重要じゃない?
「の」「は」「が」など、よく使う言葉は、実はあまり意味を持ちません。
逆に、「珍しい言葉」や「特別な表現」は、意味を強く持っていると考えます。
これを「重みづけ」といって、コンピューターが「この言葉は大事」と判断するしくみです。
つまり、よく出てくる言葉は軽く、めったに出ない言葉は重く――そんな感じです。
言葉の意味を「方向」で考える?
自然言語は前後言葉の関連性(何を言っているか)とか、類似性(同じ話?違う話?)というのを理解する必要があります。自然言語処理ではこの言葉の意味を「方向」でとらえます。ご飯の話なのか仕事の話なのか趣味の話なのかみたいなのをグラフの「右上」「左下」などの向きで表すということです。
似た意味の言葉は、同じ方向を向いている。
ちがう意味の言葉は、別の方向を向いている。
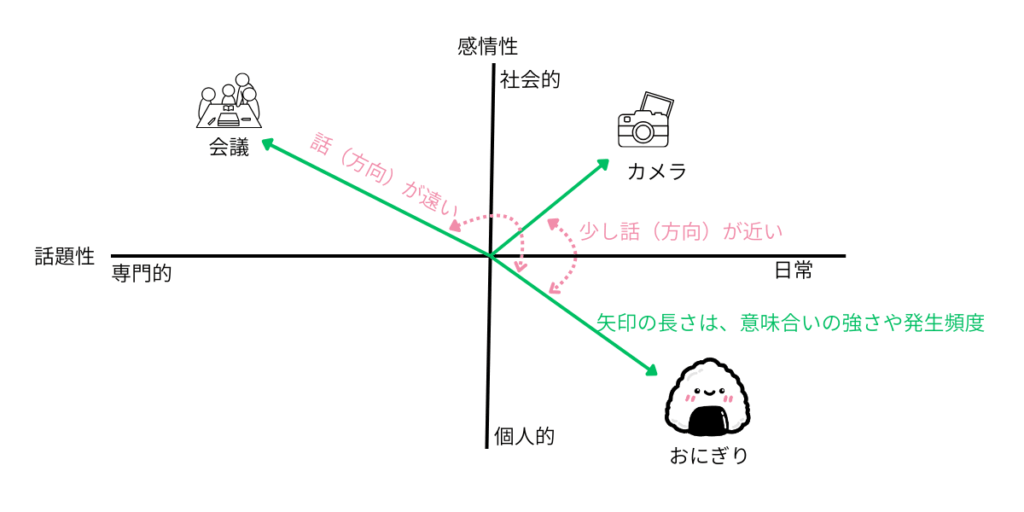
そんなふうに、コンピューターは「言葉の意味」を計算で比べるのです。
同じ方向なのかを計算するのがコサイン!
方向のちがいを調べるときに、「コサイン」という計算が使われます。
高校の数学で出てきた「サイン・コサイン・タンジェント」、覚えていますか?
「Cの形」で覚えた方もいるかもしれませんね(笑)
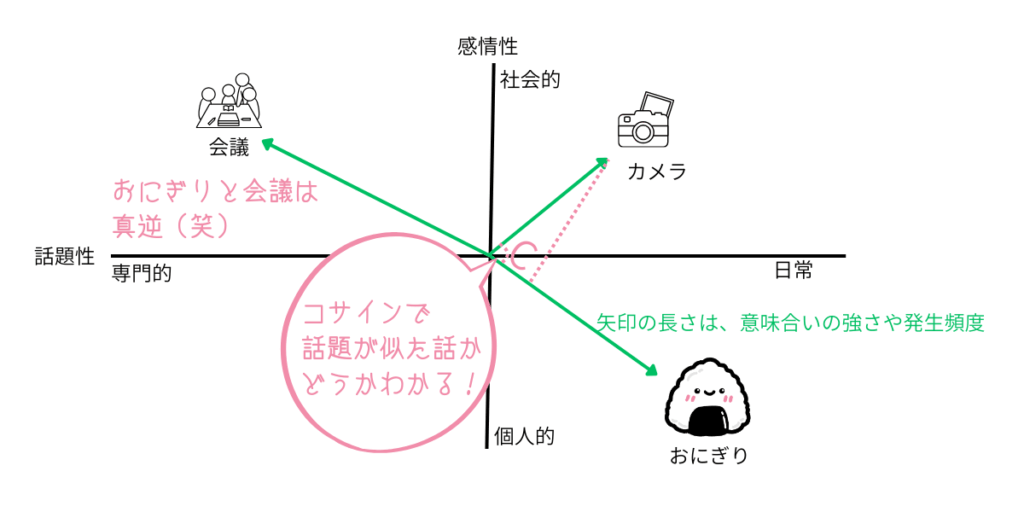
このコサインを使うと、言葉の意味が「近いか」「ちがうか」を数字で判断できます。
つまり、方向のズレ=意味の違い、というわけです。
まとめ:人の言葉をそのまま使って判断できる
このようにして、コンピューターは人の言葉を細かく分けて、意味を考え、
似ているかどうかを判断できるようになります。
これが「自然言語処理」のしくみです。
AIが私たちの言葉を理解するために、こんな工夫がされているんですね。
ちょっと身近に感じられましたか?
関連記事(シリーズ)
- 【DL超入門1】ディープラーニングとは?初心者でもわかるAIの基本と仕組み
- 【DL超入門2】ディープラーニングの学習方法 ― 回帰・分類・強化学習をわかりやすく解説
- 【DL超入門3】AI開発のカギはデータ準備 ― 良質なデータがディープラーニングを支える
- 【DL超入門4】AIが学習する仕組み ― 誤差最小化と過学習の問題をわかりやすく解説
- 【DL超入門5】「自然言語処理」ってなに?
- 【DL超入門6】ChatGPTってなに?
- 【DL超入門7】画像を処理するということは?CNNとGANのしくみをやさしく解説
- 【DL超入門8】動画(時系列データ)の扱い方 ― RNN(再帰型ニューラルネットワーク)とは?
(補足)この記事で扱ったキーワード(G検定シラバスベース)
自然言語処理, 形態素解析, 分かち書き, TF-IDF, ストップワード, 構文解析, 意味解析, 分散表現, Word2Vec, トピックモデル

コメント